
AI부트캠프의 MLOps 프로젝트가 무사히 마무리되었습니다.
저희 조의 프로젝트는 '기상청 데이터를 활용한 기온 예측 프로젝트'를 수행하였습니다.
프로젝트 기간동안에 설연휴도 끼여있고 해서 시간이 다소 촉박하게 느껴진 부분도 있었지만, 팀원들의 협업이 잘 이루어져서 다행히 무사히 잘 마쳤습니다.
우선 저희는 데이터와 모델 개발에 대한 부분도 진행하기도 하였지만, 사실 이 프로젝트의 목적이 모델에 대한 부분보다는 MLOps 구축 프로세스 이해하는 것에 목표를 두고 있는 것이기 때문에 그 부분에 더 집중해서 학습하고 프로젝트를 진행하였습니다.
프로젝트의 수행 절차는 크게보면 이렇게 5단계로 볼 수 있습니다.
1) 데이터셋 및 데이터 처리
2) 모델 개발
3) 모델 배포
4) MLOps 워크 플로우
5) 모니터링
<기본환경구축>
.env 파일

환경에 따라 변하는 환경변수는 .env 파일 통해서 관리하도록 했습니다.
.gitignore 파일

<환경세팅관리>

환경 변수에 대한 중복 코드를 줄이기 위해 Config 클래스를 만들었습니다.
<데이터 수집>
우선 데이터는 기상청 API hub 사이트 (https://apihub.kma.go.kr) 를 활용하여 데이터를 수집하였습니다.

추상 클래스를 통해 API와의 상호작용을 캡슐화하고, 변경 사항이 있을 때 추상 클래스를 상속받는 구체적인 구현만 수정하면 되기 때문에, 핵심 비즈니스 로직에는 영향을 최소화할 수 있습니다.
<데이터 수집 CLI구축>

커맨드 라인을 통해 실행 가능하도록 커맨드 구축하였습니다.
< 데이터 수집 CLI 실행>

커맨드 실행 후 로컬 디스크에 파일을 저장합니다.
<Feature store>
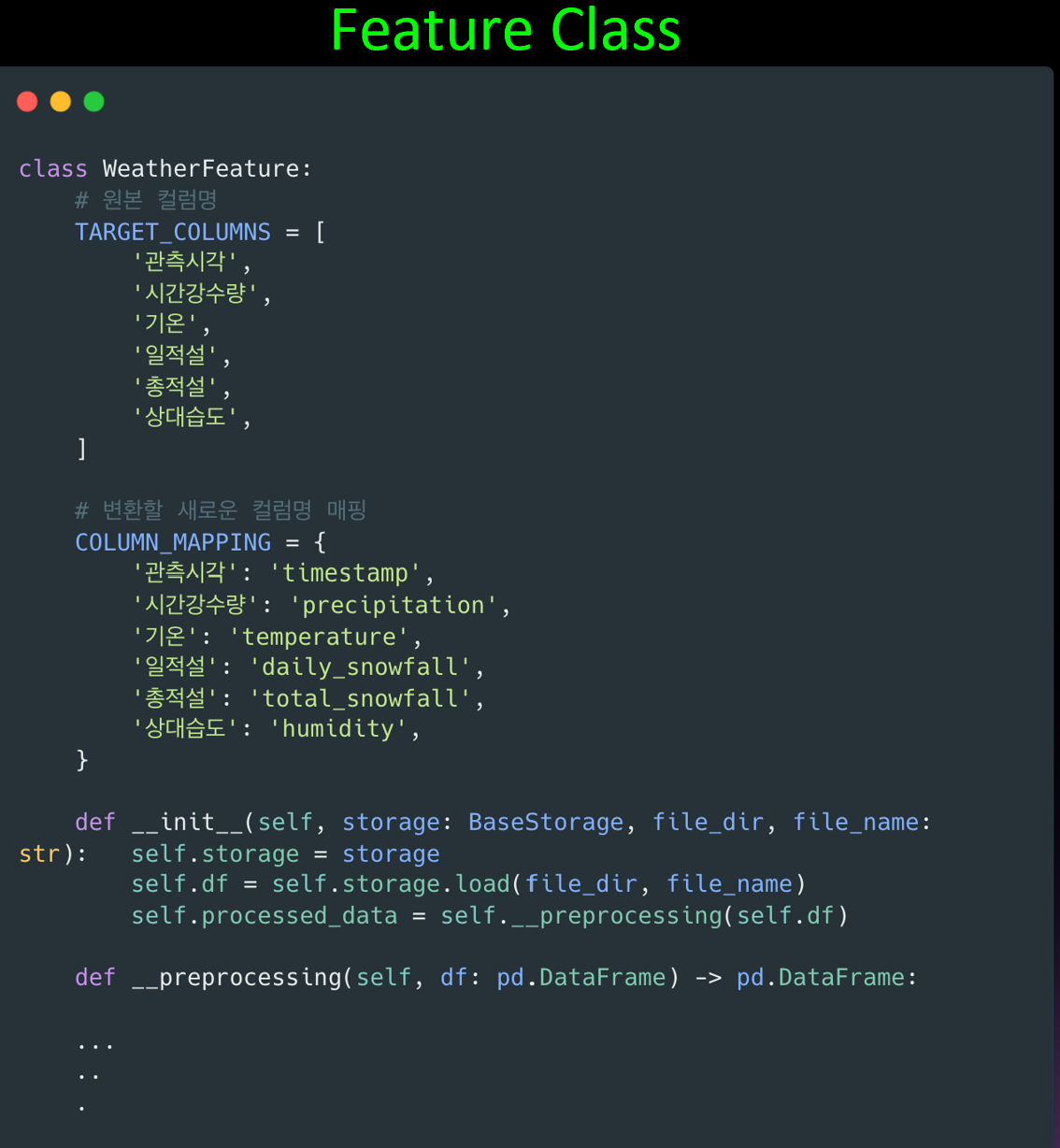
모델학습에 사용될 Feature Data는 일관된 스키마 구조를 유지하기 위헤 Feature Class를 만들었습니다.
Feature Class가 변경되면 이후 Feature를 사용하는 코드에도 영향을 끼칠수 있기때문에, 테스트 코드를 통한 안전장치를 만들고자 했습니다.
< Feature Store 저장 CLI>
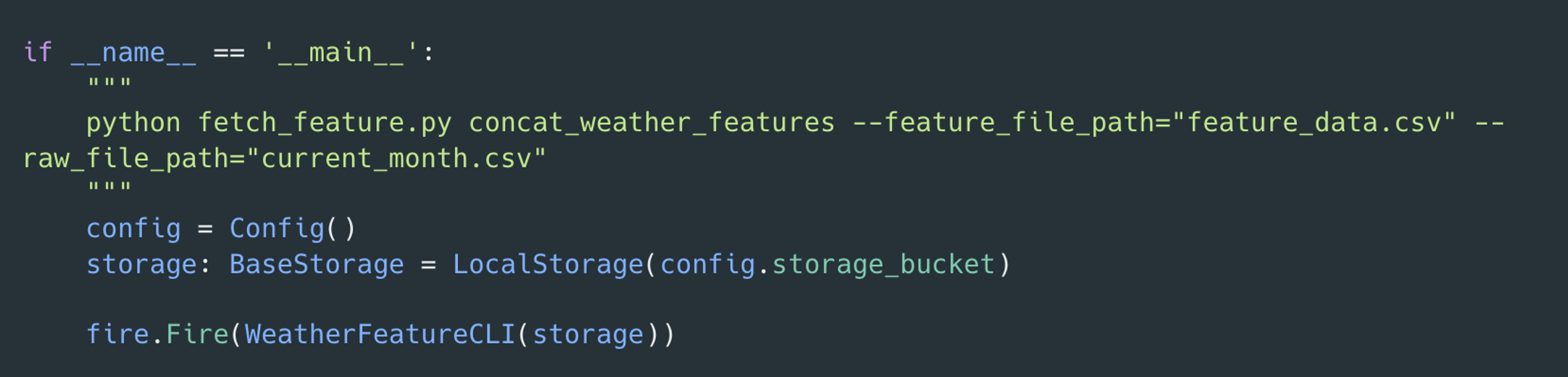
Feature Store 저장 CLI 또한 만들었습니다.
<Feature Store 데이터 변환>

원본 데이터에서 스키마 구조로 가공해서 저장된 형태입니다.
<모델 개발>
사용한 모델 : LSTM (Long Short Term Memory)
모델 선택 이유 :
--장기 의존성을 학습할 수 있음
-안정적인 학습이 가능
-기상 데이터는 시간에 따라 변화하는 연속적인 패턴이 존재
->과거 데이터를 학습하여 미래 값을 예측하는데 용이함
* 훈련 과정
- 데이터 준비: 공공 API로 데이터 수집, 전처리, 정규화, 시계열 데이터 생성
사용한 데이터 세트: datetime, tempmax, tempmin, temp
* 훈련
- 30일 데이터를 : 기반으로 다음 날 온도 예측
train. test 비율 : 8:2
* 모델 성능 지표
- RSME, MAE, R² Score
* 성능 시각화
정확도

슬랙과 코랩을 통해 전달받은 모델링 코드를 프로젝트에 적합하도록 변환하고 최적화하는 작업을 진행했습니다. 이 과정에서 데이터 구조 및 파이프라인을 재설계하여 효율성을 높였으며, 프로젝트 요구사항에 맞춘 모델 튜닝과 성능 평가를 병행했습니다.
위의 코드는 바로 실행 가능하지만 MLOps 파이프라인 완성을 위해 프로젝트에 적합한 형태로 변환할 필요가 있었습니다.
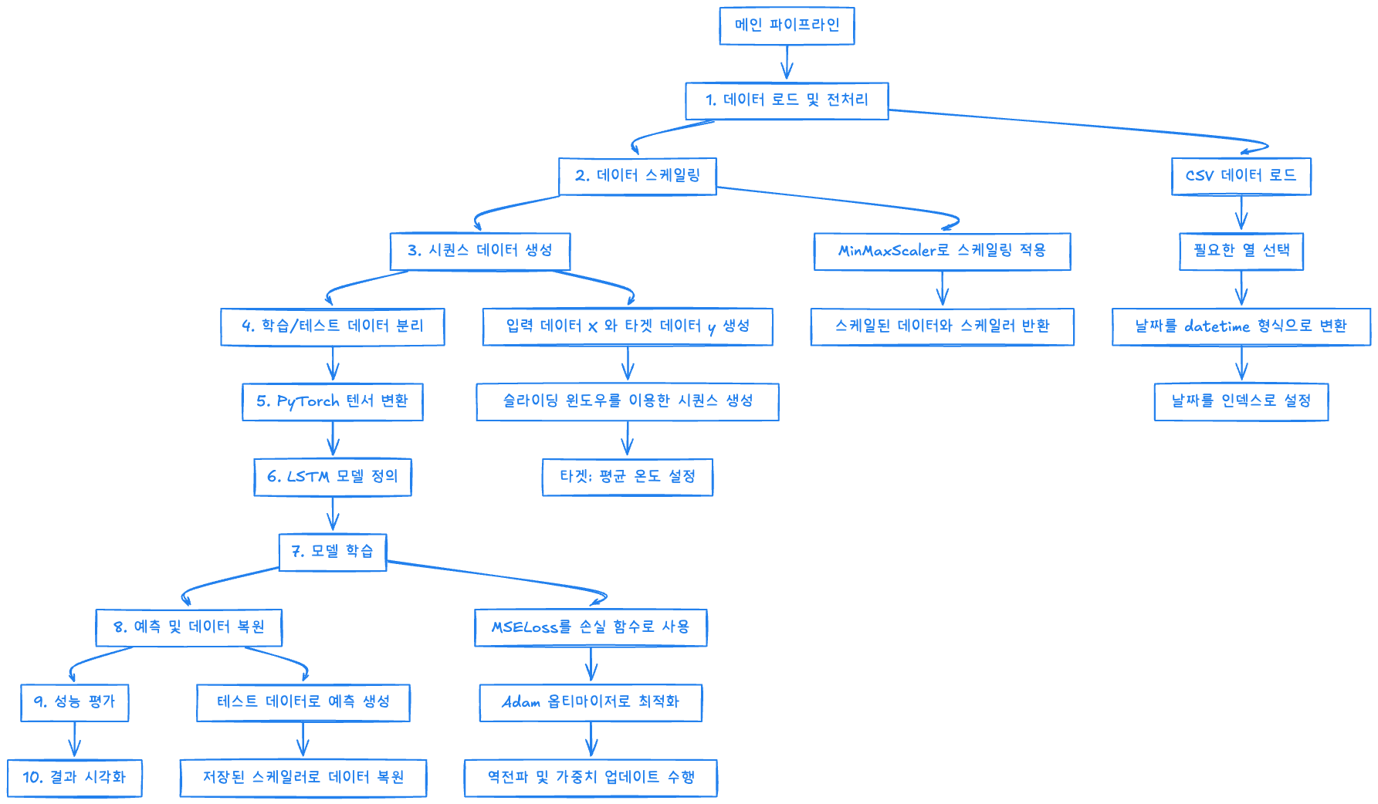
아래와 같이 레이어 별로 서로의 흐름도를 그려보면서 이해도를 쌓아갔습니다.
초기 서비스인 만큼 많은 세분화는 코드의 유연성이 떨어 질것 같아서 더 단순화 시켜볼려고했습니다.

최종적으로 간단한 구조로 도출해내었습니다.
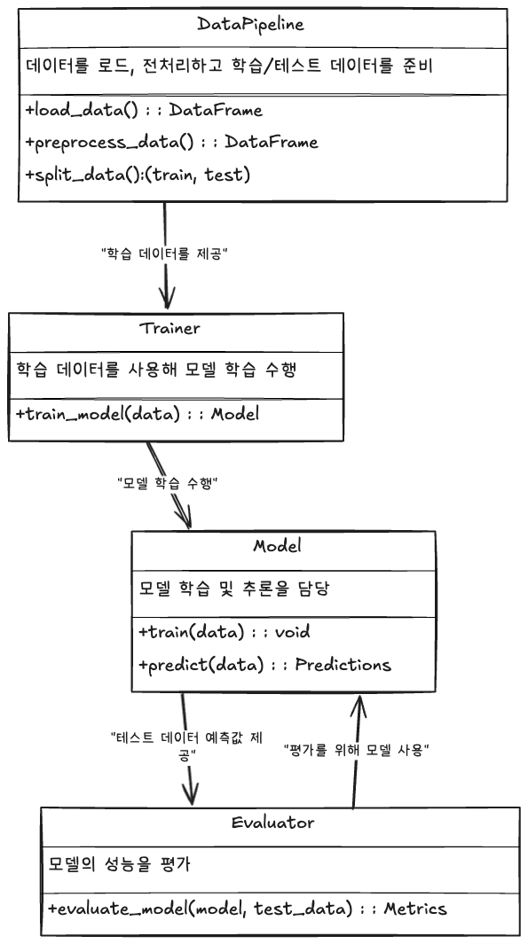
<모델 학습 CLI>

<모델 추론 CLI>

여기까지가 MLOps의 레벨 0 단계 를 구현하기 위한 시행착오에 대한 이야기 였습니다.
이를 통해 데이터 준비, 모델 학습, 평가 과정을 수동으로 관리하며, 전체 MLOps 파이프라인의 기초를 다질 수 있습니다.
< 업스테이지 서버 Model Serving>

모델 서빙을 하기위해 Fast API를 활용했습니다.
<업스테이지 서버 Model Serving>

업스테이지에서 데이터 수집 , 모델링 후 API를 통해 추론이 정상적으로 이루어지는것을 확인 할 수 있었습니다.
< 업스테이지 모델 서빙 코드 배포>

우선 업스테이지 서버의 배포는 배포 스크립트를 만들어서 추적하는 브랜치의 변경점이 있으면 FastAPI 서버를 재시작하도록 crontab 스케쥴러를 활용했습니다.
[데이터 파이프 라인 자동화]
<업스테이지 서버 Airflow 세팅>

레벨 0 까지 구현 후 매번 수집과 모델링 파이프라인을 수동으로 실행해줘야는지 고민이 되었습니다.
리눅스 스케쥴러를 사용하더라도 실패한다면 실패지점이 어디서 발생했는지 경과시간은 얼마인지 등등에 대한 이슈가 분명 있을것 같았습니다.
그런 상황에서 Airflow 가 현단계에서는 가장 구현하기 쉽고 온전한 파이썬 코드로만 구현가능하기 때문에 가장 적합하다고 생각했습니다.
<로컬 개발환경 통일화>

<자동화>

Airflow를 통해 기상청 데이터를 수집하는 flow를 만들었습니다.
<파이프라인>

Airflow를 통해 기상청 데이터를 수집하는 flow를 만들었습니다.
<Airflow Dataset>

<모델학습>

[모델 훈련 서빙 재시작]

<모델 추적 관리>
우선 업스테이지 서버의 배포는 배포 스크립트를 만들어서 추적하는 브랜치의 변경점이 있으면 FastAPI 서버를 재시작하도록 crontab 스케쥴러를 활용했습니다. 이 단계에서는 MLFlow를 활용하여 프로세스를 진행하였습니다.
<AWS s3 모델 저장>

<MLFlow 데이터 비교>

<모델 버전 관리>
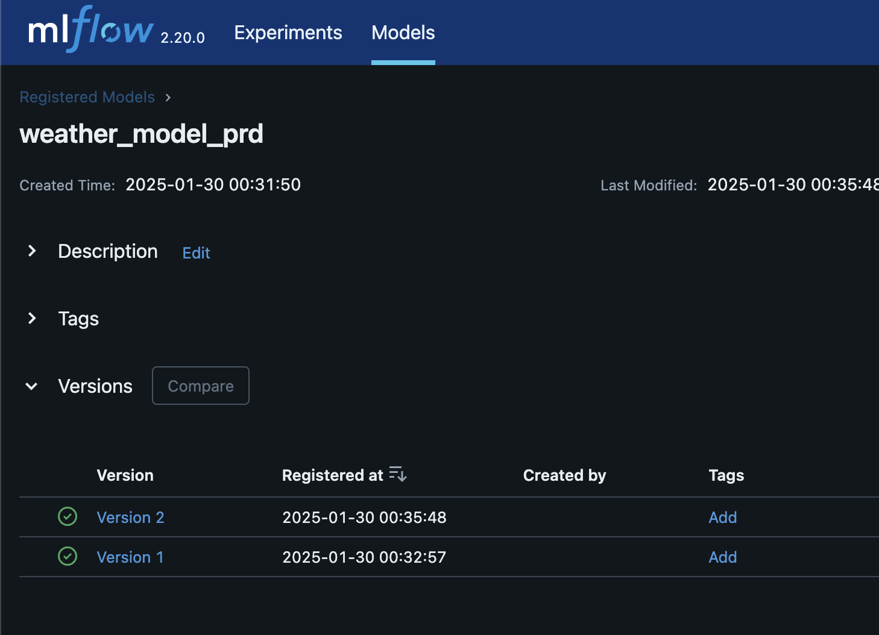
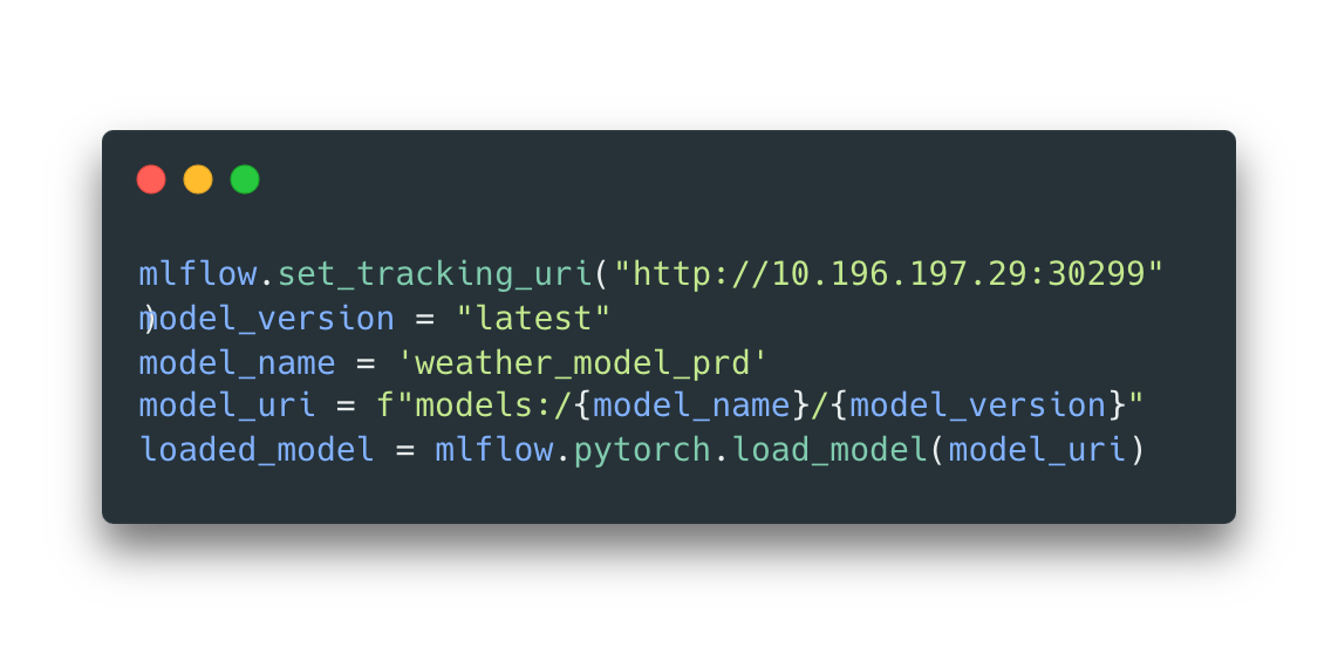
<최신 모델 서빙>
[배포]

Deploy Workflow

<회고>
2주라는 기간동안에 MLOps 의 모든 프로세스를 깊이 있는 이해를 하기에 촉박한 시간이었지만, MLOps 라는 것에 대해서 전체적인 프로세스를 경험해볼 수 있는 의미있는 프로젝트였다고 생각합니다. AI부트캠프에서 이러한 경험들이 계속 쌓이다 보면 나중에 회사에 입사하여 실무를 하는데에도 도움이 될거라고 생각합니다.
AI부트캠프에서 다음 경진대회는 딥러닝과 Computer Vision 기술을 활용한 CV 경진대회가 예정되어 있습니다. 딥러닝과 Coumputer vision 기술 모두 제가 관심이 있던 분야였는데, 다음에는 더 열공해서 좋은 성과를 이룰 수 있으면 좋겠습니다.
#AI 부트캠프 # 딥러닝 #패스트캠퍼스 #부트캠프 #국비지원취업 #국비지원